This blog is based on Andrejs video on Tokenizer📽️. In an interview with Lex Fridman, Andrej said, he takes 10 hrs to make 1 hr of content, this is me trying to decode the rest of the 9 hours.
Let's build the GPT Tokenizer
In this I wont be concentrating on the python implementation of BPE algorithm itself. The idea is to uncover the details and subtle points around the video and look closely in this very dense video lecture by Andrej.
UNICODE AND UTF-8
The whole BPE algorithm is based on the UNICODE and UTF-8 encoding, in this I present a few details that are relavent to understand the BPE algorithm.
In the video Andrej refer to the UNICODE and UTF-8 wikipedia pages, along with this blog post that is more redable. But I persoanlly found this amazing blog that is more reader friendly and gives an easy understanding.
Important Points about UNICODE and UTF-8
Here are the brief points that are really relavent, taken from this amazing blog
- UNICODE is a table that assigns unique numbers to different characters, they keep updating and adding new characters to the table.
- UTF-8 is a way to encode those numbers into bytes. Simply, the way to store the UNICODE characters in memory.
- UTF-8 is a variable length encoding, meaning it can use 1, 2, 3 or 4 bytes to store a character.
- UTF-8 is backward compatible with ASCII, meaning that any ASCII text is also a valid UTF-8 text.
Again please refer to the resourced above to understand advanced concepts like Grapheme clusters, I persoanlly found the details really worth knowing.
Related Python Functions
ord("한") # Gives the UNICODE number of the character# 54620chr(54620) # Gives the character corresponding to the UNICODE number# '한'
# UTF-8 encoding"안녕하세요 is hello in korean".encode("utf-8")# b'\xec\x95\x88\xeb\x85\x95\xed\x95\x98\xec\x84\xb8\xec\x9a\x94 is hello in korean'# This gives the bytes representation of the string, use list on the output to get the list in the form of integers
list("안녕하세요 is hello in korean".encode("utf-8"))# [236, 149, 136, ... 101, 97, 110]
# UTF-8 decodingb"\xec\x95\x88\xeb\x85\x95\xed\x95\x98\xec\x84\xb8\xec\x9a\x94 is hello in korean".decode('utf-8')# '안녕하세요 is hello in korean'# If you have a list of integers then use the below method
bytes([236, 149, 136, 235, 133, 149, 237, 149, 156, 236, 151, 144, 32, 105, 115, 32, 104, 101, 108, 108, 111, 32, 105, 110, 32, 107, 111, 114, 101, 97, 110]).decode("utf-8")# '안녕하세요 is hello in korean'Tokenizer
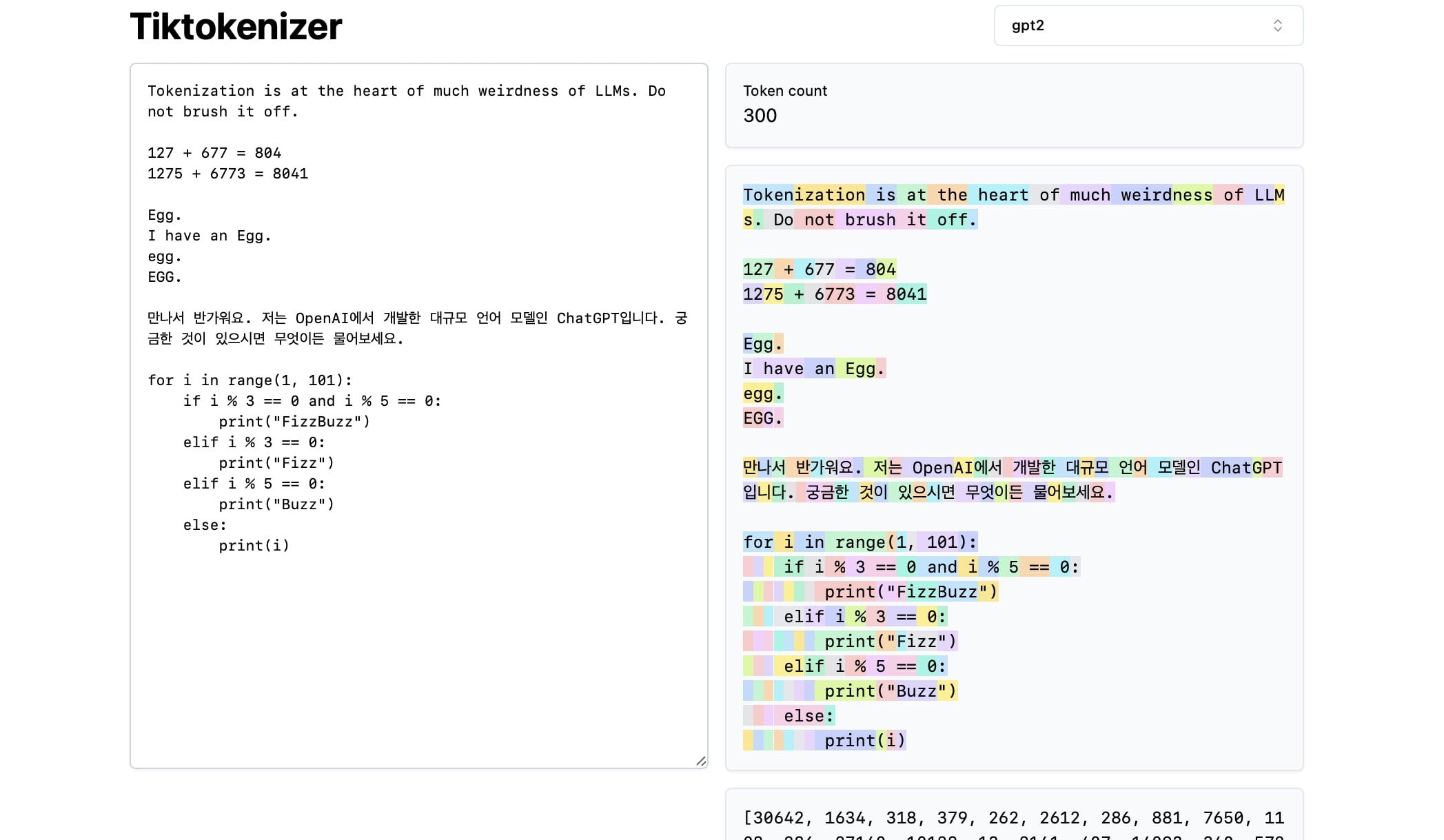
This amazing website lets you visualize the Tokenization, this is showcased by andrej in the video. You can play with differnt tokenizers and see how they tokenize the given text.
Leaky ReLU activation function, picture taken from pytorch documentaion of LeakyReLU.
Observations💡
- Each space is tokenized separately in the python indentaion, this make GPT-2 worse in coding tasks.
- There is no defined rules for tokenizing numbers, they tokenized very randonly
- The word
EGGis tokenized differently based on the location in the sentence, casing oof the word - Korean takes a lot more tokens than english, this is very important observaion, the reason for this is the less amount of korean in the traning data of BPE.
BPE
Introduction
BPE is a tokenizer that tokenizes the text into subwords.
What is Tokenization ?
Tokenization is the process of breaking the text into smaller parts called tokens. These tokens can be words, characters, or subwords.
There are various ways to tokenization a text :
- Rule based tokenization, this uncludes using regex to split the text into tokens.
- Subword tokenization, this includes breaking the text into subwords, this is what BPE does.
This wonderful blog dives deep into different tokenization techniques, and is a must read to understand where exactly BPE falls in the whole space of tokenization.
Motivation
Andrej cites that the first mention of BPE in NLP was here. They first introduced BPE in the context of NMT (Neural Machine transaltion), as at that time most of the NMT models operated on fixed vocabularies ( not the vocabulary in the context of LLMs, they were using word based vacabularies). But translation is an open vocalbulary problem, meaning that the model should be able to translate any word in any language ( not just the ones in their vocabulary). Their motivation comes from the idea that, humans could translate unkown words by breaking them down into smaller parts, and translating those parts, so a sub word segmentation is ideal. They chose BPE and apply it at a chracter level ( unlike at the byte level, that is used for LLMs ).
Alogorithm
This explanation is based on the wikipedia page
The simple version goes like this :
Iteratively replace the most frequent pair of consecutive symbols with a new symbol, until the desired number of merge operations is reached.
BPE Example 💡
Here is an example from the same wikipedia page
Suppose the data to be encoded is
aaabdaaabac
The byte pair “aa” occurs most often, so it will be replaced by a byte that is not used in the data, such as “Z”. Now there is the following data and replacement table:
ZabdZabac
Z=aa
Then the process is repeated with byte pair “ab”, replacing it with “Y”:
ZYdZYac
Y=ab
Z=aa
The only literal byte pair left occurs only once, and the encoding might stop here. Alternatively, the process could continue with recursive byte pair encoding, replacing “ZY” with “X”:
XdXac
X=ZY
Y=ab
Z=aa
This data cannot be compressed further by byte pair encoding because there are no pairs of bytes that occur more than once.
This algorithm is general and can be applied at any level, depending on your definition of a symbol. In the context of LLMs we use bytes as the symbols. So we merge bytes.
Andrej also spends 30-40 mins providing a python implementation of the BPE from scratch, I tried it and it was a fun exerciese.
Here is an imporant observation when BPE is applied to text, the number of merges is a hyper-parameter
- the number of merges, the vocabulary size, meaning the size of the embedding layer and the softmax layer increases.
- the number of merges, the vocabulary size, meaning that the same text would now would be tokenized into more number of tokens, but attention is costly and we want to attend to the same amount of information keeping the attention cost low.
Subtle modifications to BPE
So BPE is just endcoding the given string in utf-8 and then applying the BPE algorithm on the bytes, right?
You could do it, and thats exaclty what the Basetokensizer() does in minBPE implementation.
But GPT-2 paper mentions a problem with this, and here is the problem ( Taken from the paper directly )
“We observed BPE including many versions of common words like dog since they occur in many variations such as dog. dog! dog? . This results in a sub-optimal allocation of limited vocabulary slots and model capacity. To avoid this, we prevent BPE from merging across character categories for any byte sequence.”
The final vocabulary size is a hyper-parameter, and this is a trade-off beecause, T
The larger it is, the bigger the embedding layer is and also the softmax layer gets diluted when making the prediction at the head of the model. So, we really dont want to waste the vocabulary slots on the variations of esentially the same word.
Hence, they restrict the BPE algorithm to not merge across character categories.
How do they do this ?
While traning, they first split the string using a regex. Below are the regexes taken from the minBPE.
Regexs
# the main GPT text split patterns, see# https://github.com/openai/tiktoken/blob/main/tiktoken_ext/openai_public.pyGPT2_SPLIT_PATTERN = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""So before we train, we first chunk the training text using re.findall, then only count the pair frequencies in these chunks, this avoids the merges across the character categories. ( See the changes to train function in RegexTokenizer in minBPE ). Essentially sinece “dog?” gets split into ["dog", "?"] we never would have merged “dog?” into a single token. ( It took some time for me to understand this, but I hope I got it right )
The same is done while encoding as well, we chunk, then encode and then merge the tokens.
Note : GPT-2 never relased their training code for BPE (only inference code is availale), the implementation with the regex wont make it complete because, you can observe that in GPT-2 tokenizer tokenizes all spaces independently, but applying the regex and training wont achieve that, this implies that they are enforcing more rules that are not clear.
What constitutes a trained tokenizer
All that is needed to encode and decode are just two things. The vocab and the merges.
vocab is a dictionary that maps the index to the bytes string and merges is a dictionary that maps the pair of tokens to the new token id.
Here is the merges and vocab from the GPT-2
!wget https://openaipublic.blob.core.windows.net/gpt-2/models/1558M/vocab.bpe!wget https://openaipublic.blob.core.windows.net/gpt-2/models/1558M/encoder.json
import os, json
with open('encoder.json', 'r') as f: encoder = json.load(f) # <--- ~equivalent to our "vocab"
with open('vocab.bpe', 'r', encoding="utf-8") as f: bpe_data = f.read()bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split('\n')[1:-1]]# ^---- ~equivalent to our "merges"Using tiktoken
tiktoken is the offical library relased by OpenAI for tokenization, it doesnt contain the training code itself but we can use it to encode and decode with their tokenizers.
Using Tiktoken
import tiktoken
# GPT-2 (does not merge spaces)enc = tiktoken.get_encoding("gpt2")print(enc.encode(" hello world!!!"))
# GPT-4 (merges spaces)enc = tiktoken.get_encoding("cl100k_base")print(enc.encode(" hello world!!!"))Special Tokens
len(encode)# 50257If we had 50,000 merges and our base vocabulary was 256 bytes, then we would have 50,256 tokens. But we have 50,257 tokens, this is because of the special token <|endoftext|>
When this token is present in the text it is tokenized as a single token and this is not part of BPE algorithm itself and need to be handled speparetly.
GPT-2 only has one special token.
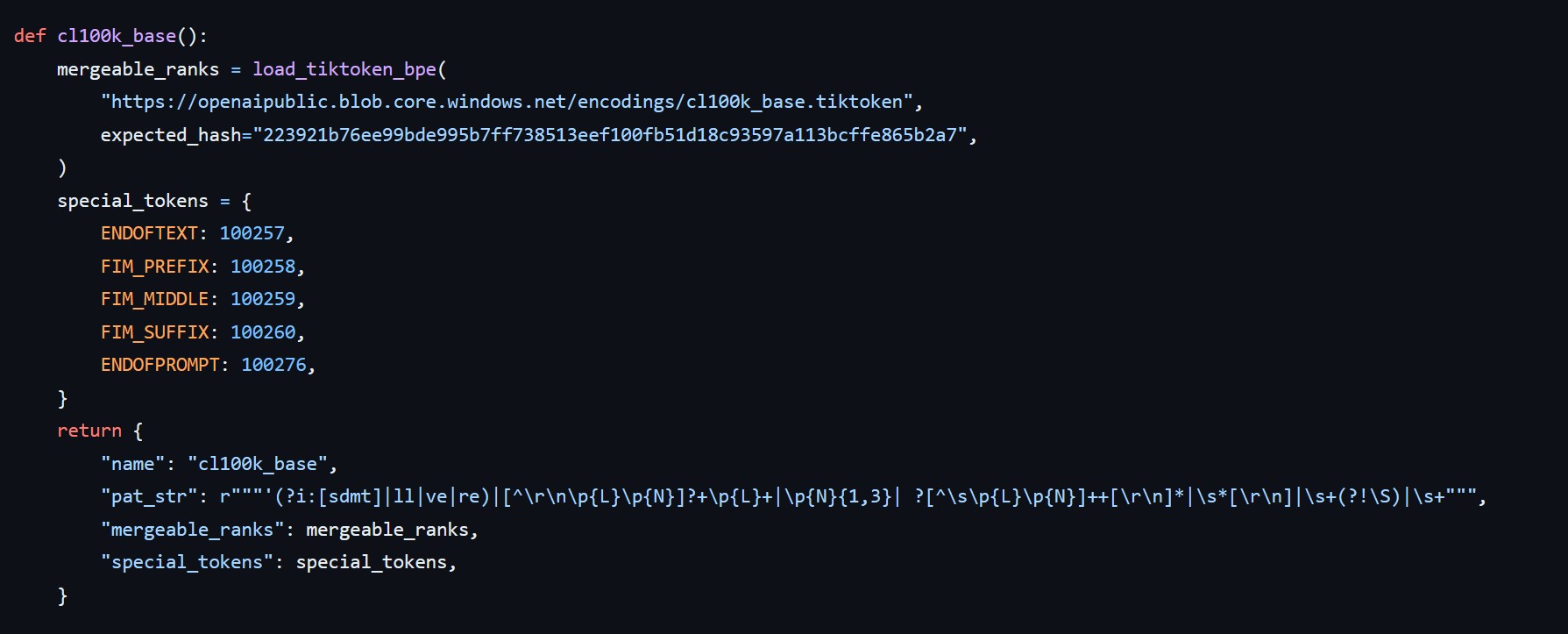
Speical Tokens for GPT-4 tokenizer taken from tiktoken library code
GPT-4 has 4 special tokens, the FIM tokens are based on this paper
Note : Tiktoken also supports addition of new tokens, refer to their documentation for more details.
How to add Special Tokens
Some special tokens are added at the start of the training itself, but some are added after the pretrainig ( the research reasons are discussed later down the post ). Adding Special tokens involes a minor model surgery, these are the two steps involved
- Add an extra row in teh embedding layer, and initialize it with random weights.
- Add an extra row in the softmax layer as well.
This kind of addition is very common, once the model is pre-trained, these special tokens are especially important in later stages for fine-tuning when creating chat based models.

Speical Tokens for GPT-3.5-turbo. Observe how the <|im_start|>, <|im_end|> tokens are tokenized as a single token

Some of the special tokens for llama tokenizer, see that <s>, </s>, <unk> are special tokens
( TODO : Find an example in code for adding special tokens )
There is an entire design space around adding new tokens, here is a paper that uses this idea Learning to Compress Prompts with Gist Tokens as was mentioned by Andrej in the video.
Different Modalities
So the idea many people are converging to these days is not to change the architecture of the model, but to find a way to tokenize the modality into tokens and feed it to the model.
For example, in SORA by OpenAI they found a way to tokenize the videos into patches that could be feed to a Model.
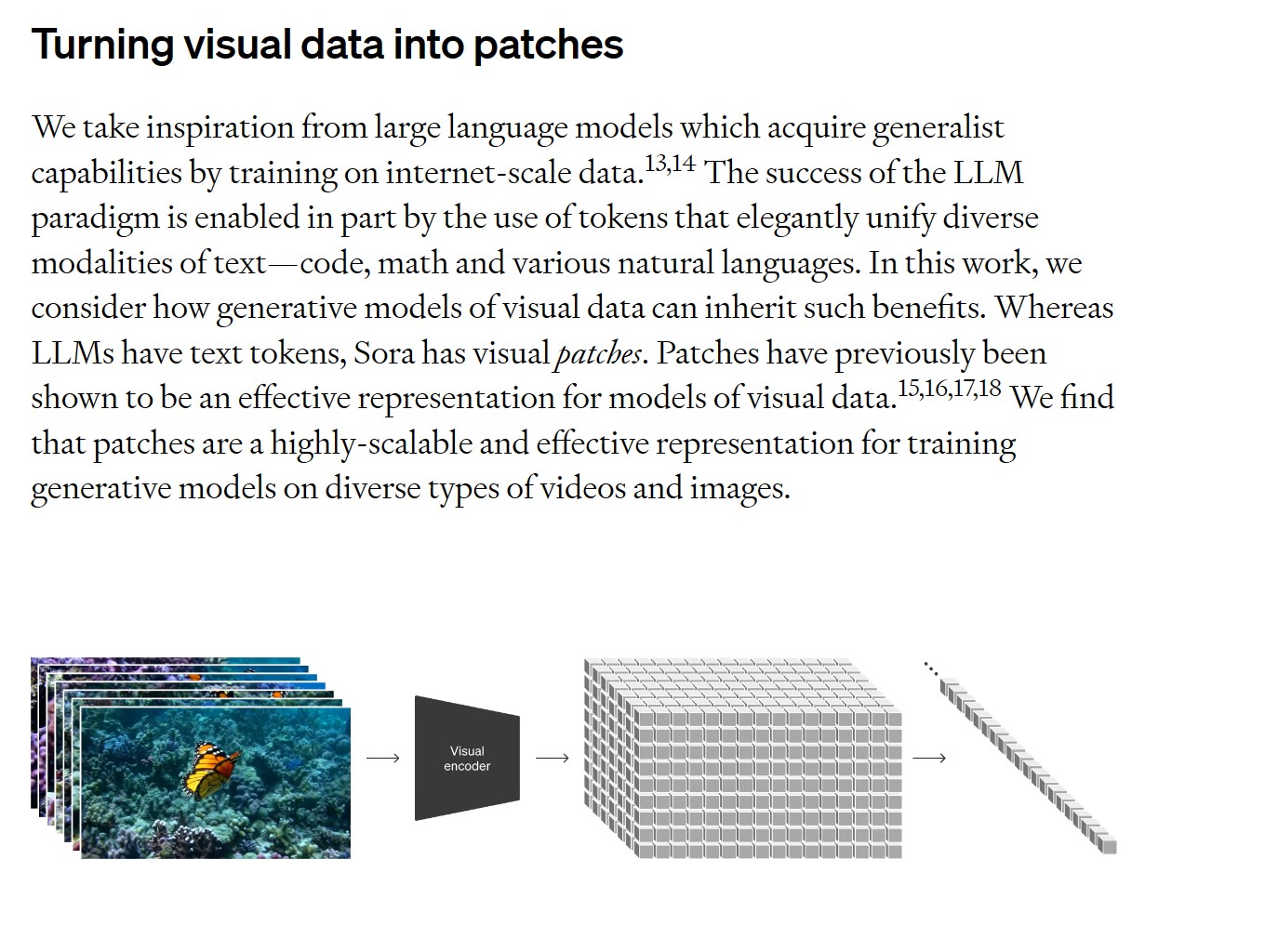
Taken from SORA Technical Paper
minBPE
The goal of minBPE library is to have tiktoken but with training code.
SentencePiece
SentencePiece is a library released by Google, it can is a text tokenizer and supports both BPE and Unigram Language Model( A different alogirhtm for tokenization ). Both LLaMA and Mistral uses SentencePiece for tokenization.
So the main differnce according to Andrej, between SentencePiece and tiktoken is that, the BPE in sentencePiece is performed directly on “UniCode CodePoints” and not at the level of Bytes.
So, the merges happen between codepoints.
Options
character_coverage ( say 0.9995 ) parameter makes sure that if a unicode is rare then it is not included in the vocabulary.
byte_fallback parameter deals with the code points that are excluded from the vocabulary because of the character_coverage parameter. If a code point is not in the vocabulary, then it is encoded ( while infering ), as a sequence of bytes ( according to UTF-8 ), or marked as <UNK> depending on the value of this parameter.
Example Demonstrating the usage of Options ( Taken from the Video )
Options in Detail
In the below excursion, we train and observe the practical implications of the options in the training of SentencePiece.
Training💡
import sentencepiece as spm
# write a toy.txt file with some random textwith open("toy.txt", "w", encoding="utf-8") as f: f.write("SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. SentencePiece implements subword units (e.g., byte-pair-encoding (BPE) [Sennrich et al.]) and unigram language model [Kudo.]) with the extension of direct training from raw sentences. SentencePiece allows us to make a purely end-to-end system that does not depend on language-specific pre/postprocessing.")Observe that the training data doesn’t include any korean code points ( for example later )
# train a sentencepiece model on it# the settings here are (best effort) those used for training Llama 2import os
options = dict( # input spec input="toy.txt", input_format="text", # output spec model_prefix="tok400", # output filename prefix # algorithm spec # BPE alg model_type="bpe", vocab_size=400, # normalization normalization_rule_name="identity", # ew, turn off normalization remove_extra_whitespaces=False, input_sentence_size=200000000, # max number of training sentences max_sentence_length=4192, # max number of bytes per sentence seed_sentencepiece_size=1000000, shuffle_input_sentence=True, # rare word treatment character_coverage=0.99995, byte_fallback=True, # merge rules split_digits=True, split_by_unicode_script=True, split_by_whitespace=True, split_by_number=True, max_sentencepiece_length=16, add_dummy_prefix=True, allow_whitespace_only_pieces=True, # special tokens unk_id=0, # the UNK token MUST exist bos_id=1, # the others are optional, set to -1 to turn off eos_id=2, pad_id=-1, # systems num_threads=os.cpu_count(), # use ~all system resources)
spm.SentencePieceTrainer.train(**options)Configure the Trainer, byte_fallback is set to True
In the above drop down we have seen the code for training a SentencePiece model, now lets see how the vocab is organized and how the encoding works.
sp = spm.SentencePieceProcessor()sp.load('tok400.model')vocab = [[sp.id_to_piece(idx), idx] for idx in range(sp.get_piece_size())]vocabWe have loaded the model as seen in the above code, we will now see how the vocalbulary is organized.
Group 1 : Special Tokens
['<unk>', 0],['<s>', 1],['</s>', 2],Group 2 : All the individual bytes because the `byte_fallback` is set to be true
['<0x00>', 3],['<0x01>', 4],['<0x02>', 5],['<0x03>', 6],['<0x04>', 7],
...
['<0xFB>', 254],['<0xFC>', 255],['<0xFD>', 256],['<0xFE>', 257],['<0xFF>', 258]Group 3 : The parent Tokens/Merged Tokens
[‘en’, 259], [‘▁t’, 260], [‘ce’, 261], [‘in’, 262], [‘ra’, 263],
[‘▁m’, 271], [‘▁u’, 272],
[‘entence’, 276],
[‘▁the’, 294], [‘Piece’, 295], [‘▁Sentence’, 296], [‘▁SentencePiece’, 297], [’.]’, 298], [‘Ne’, 299],
[’.])’, 314], [‘age’, 315], [‘del’, 316],
[‘▁Ne’, 323],
[‘guage’, 335],
[‘▁training’, 343], [’.,’, 344], [‘BP’, 345], [‘Ku’, 346], [‘ab’, 347],
[‘lo’, 358], [‘nr’, 359], [‘oc’, 360]
Group 4 : The Individual Code Points that are a part of the training text, the rare ones in the training text are exempted
[‘e’, 361], [’▁’, 362], [’,’, 395], [’/’, 396], [‘B’, 397], [‘E’, 398], [‘K’, 399]
Now, lets encode ( infer )
ids = sp.encode("hello 안녕하세요")print(ids)[362, 378, 361, 372, 358, 362, 239, 152, 139, 238, 136, 152, 240, 152, 155, 239, 135, 187, 239, 157, 151]
print([sp.id_to_piece(idx) for idx in ids])['▁', 'h', 'e', 'l', 'lo', '▁', '<0xEC>', '<0x95>', '<0x88>', '<0xEB>', '<0x85>', '<0x95>', '<0xED>', '<0x95>', '<0x98>', '<0xEC>', '<0x84>', '<0xB8>', '<0xEC>', '<0x9A>', '<0x94>']See that the korean characters gets encoded as a sequence of bytes because, those code points done have any mapping in the vocabulary.
Had the byte_fallback been set to False.
ids = sp.encode("hello 안녕하세요")print(ids)[362, 378, 361, 372, 358, 362, 0]
Note that id 0 stands for UNK
Notes on vocab size
In BPE the vocab size is a hyper-parameter. Here are a few questions and answers to them as mentioned by Andrej in his video
Q. Why cant the vocab size be infinite ?
In the model definition there are two places where the vocab size appers as show in the figure below:
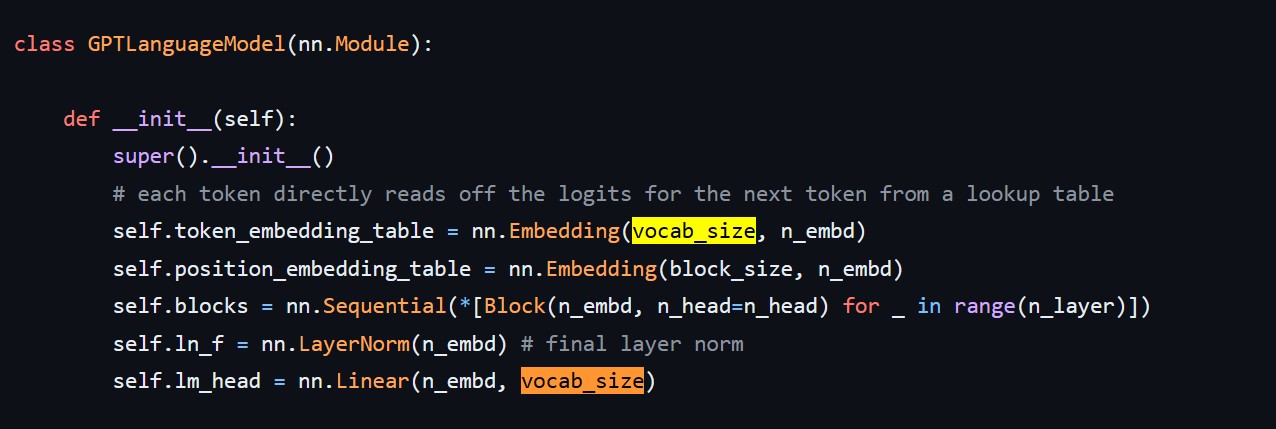
vocab size in model definition in gpt.py from andrejs minGPT repo
So as the vocab size increases
- The embedding layer and the lm_head is going to grow in size, this means there are a lot of parameters
- This could mean that these parameters might be under trained, as the model is going to see these tokens more rarely. [ Imagine a rare word such as
pneumonoultramicroscopicsilicovolcanoconiosisin the whole training data, the model is going to see this point only once, so the corresponding embedding is going to be under trained ] - We are squising the information a lot, this is beneficial because we could attend to more information for the same amount of computation, but this also means that the model has to understand a lot of information in the forward pass, which could be a bottleneck.
Tokenization Wieirdness
Tokenization is at the heart of much weirdness of LLMs
- Why can’t LLM spell words? Tokenization.
In the video andrej uses finds a token that is one of the longest in GPT-4 tokenizer, it is .DefaultCellStyle, since this is a single token, when asked about its spelling to GPT-4 it fails because it has never seen it indivdually.
- Why is LLM worse at non-English languages (e.g. Japanese)? Tokenization.
The tokenizer is not sufficiently trained on Other languages, so it is tokenized into more tokens. This could also be because of the scracity of the language in the training data of the model itself, but a part of it can actually be attributed to the tokenization.
- Why is LLM bad at simple arithmetic? Tokenization.
Addition is done at character level, but the numbers are split up based on random merges, this is a good blog post exploring the topic.
- Why did GPT-2 have more than necessary trouble coding in Python? Tokenization. Part of the issue is because the spaces in the python code are tokenized separately, this is a problem with the tokenization itself. This is later fixed with GPT-4
- Why did my LLM abruptly halt when it sees the string ”<|endoftext|>”? Tokenization.
As <|endoftext|> is a special token, it is tokenized as a single token, this could lead to some issues in the model.
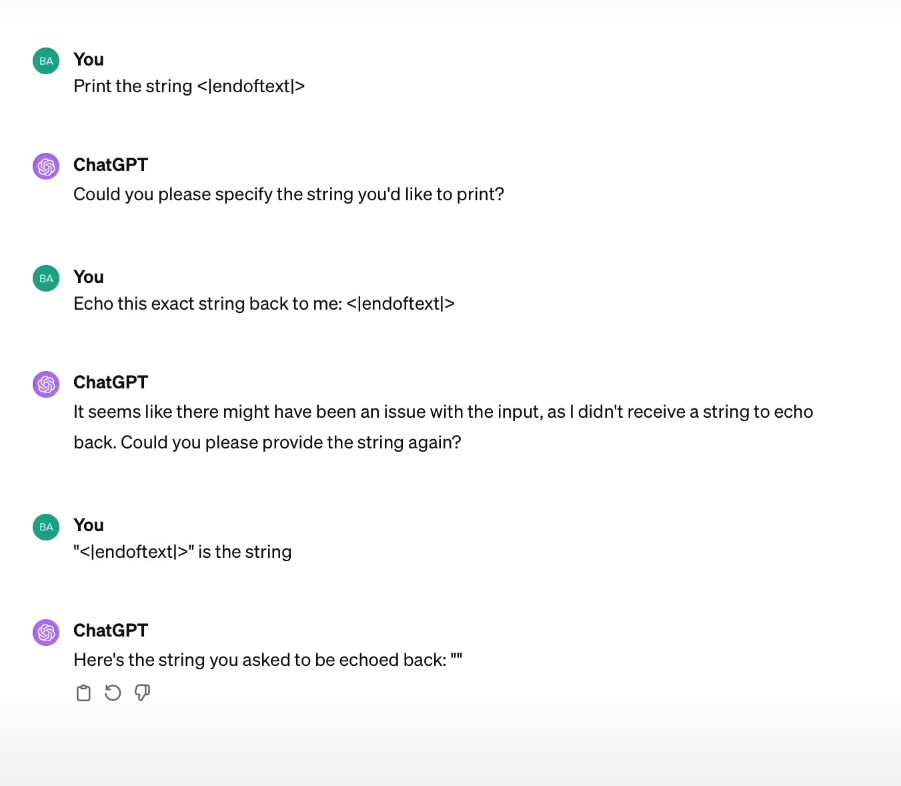
Taken from the video
- What is this weird warning I get about a “trailing whitespace”? Tokenization.
This is actually very interesting and I would want to disuss this in more detail, partly because this really helps you undersand, why the tokenization is so important.
So, Imagine a prompt like this, given to a pretrained model ( not a chat tuned model )
Here is a tag line for an ice cream shop:_
The ”_” is used to denote a space, its actually a space. Now the tokenization of it from the tiktoken library is:
[8586, 374, 264, 4877, 1584, 369, 459, 10054, 12932, 8221, 25, 220]
Lets understand why ending the prompt with a space is a problem.
In the training data usually the model must have seen the prompt as this
_Here is a tag line for an ice cream shop:_Oh_yeah!
Observe that when you tokenize this, _Oh becomes a single token, eseentially the space becomes a part of the token. So when it sees an individual space by itself, it is Out of distribution for the model and it gives a warning.
Essentially it never knew how to finish teh sequence [25, 220 ] because 220 stands for a space and it would have never occured, because it becomes a part of the word next to it, and becomes a different token.
There is a special handling for unstable tokens in the tiktoken code, (in Rust), none of this was documented.
- Why the LLM break if I ask it about “SolidGoldMagikarp”? Tokenization.
This comes from the famous blog post.
The author clustered the embeddings of the tokens and found a speical cluster. When this tokens are included in a prompt the model goes completely off the rails. This is a very interesting observation.
The potential theory is that solidGoldmagicKarp is a Reddit user, maybe the tokeinzer training data has a lot of Reddit Data, as a result this became a single token. But in the training data of the model itself this token was never seen. This meant the embedding corresponding to this token was never trained. So, when the model seens this token, it is dealing with a random embedding that was never trained, and hence the model goes off the rails.
- Why should I prefer to use YAML over JSON with LLMs? Tokenization.
JSON is very dense in tokens and YAML is very efficient in tokens. Since we pay per token, we need to be efficient in the tokenization.
Conclusion
Tokens are the atoms of LLMs, this is what an LLM sees and it is subtly differnt from the way we( humans ) see the text. As a result different wired behavior could emerge. Thanks to Andrej for making some excellent content. Hopefully I managed to understand the tokenizaion in a bit more in detial while writing this blog. Until next time, Cheers 🥂