Here are a few observations:
GPT-2, developed by OpenAI, opts for the GELU (Gaussian Error Linear Unit) activation function
On the other hand, LLaMA, a creation of Facebook Research, embraces SwiGLU activation function.
Meanwhile, Gemma, a PyTorch implementation by Google, adopts GeGLU activation functions.
So what are these new activation functions ? How should one go about implementing them in pytorch ?
In this blog post I try to understand the definitions of these activation functions and how they could be implemented in pytorch. At the end I will show the definitions from the actual implementaions in GPT-2, Gemma and LLaMA.
Imports
import torchimport torch.nn as nnCreate a new tensor with random values to use it as input for the activation functions
tensor = torch.randn(10)print(tensor)print(tensor.shape)tensor([-0.8281, 1.0340, -0.4363, -0.4764, 0.6419, -0.1156, 1.4339, 1.5654, 0.7124, -0.5667]) torch.Size([10])
RELU Variants
RELU
Rectified Linear Unit
relu = nn.ReLU()output = relu(tensor)print(output)tensor([0.0000, 1.0340, 0.0000, 0.0000, 0.6419, 0.0000, 1.4339, 1.5654, 0.7124, 0.0000])
CReLU
Concatenated ReLU
Observe that the dimension of the output tensor is twice the input tensor.
crelu_output = torch.cat((relu(tensor), relu(-tensor)))print(crelu_output)tensor([0.0000, 1.0340, 0.0000, 0.0000, 0.6419, 0.0000, 1.4339, 1.5654, 0.7124, 0.0000, 0.8281, 0.0000, 0.4363, 0.4764, 0.0000, 0.1156, 0.0000, 0.0000, 0.0000, 0.5667])
Leaky ReLU
leaky_relu = nn.LeakyReLU( negative_slope=0.1)output = leaky_relu(tensor)print(output)tensor([-0.0828, 1.0340, -0.0436, -0.0476, 0.6419, -0.0116, 1.4339, 1.5654, 0.7124, -0.0567])
ReLU6
relu6 = nn.ReLU6()output = relu6(tensor)print(output)tensor([0.0000, 0.8944, 0.0000, 0.6875, 0.0526, 0.0000, 0.0000, 0.0000, 1.1088, 0.0000])
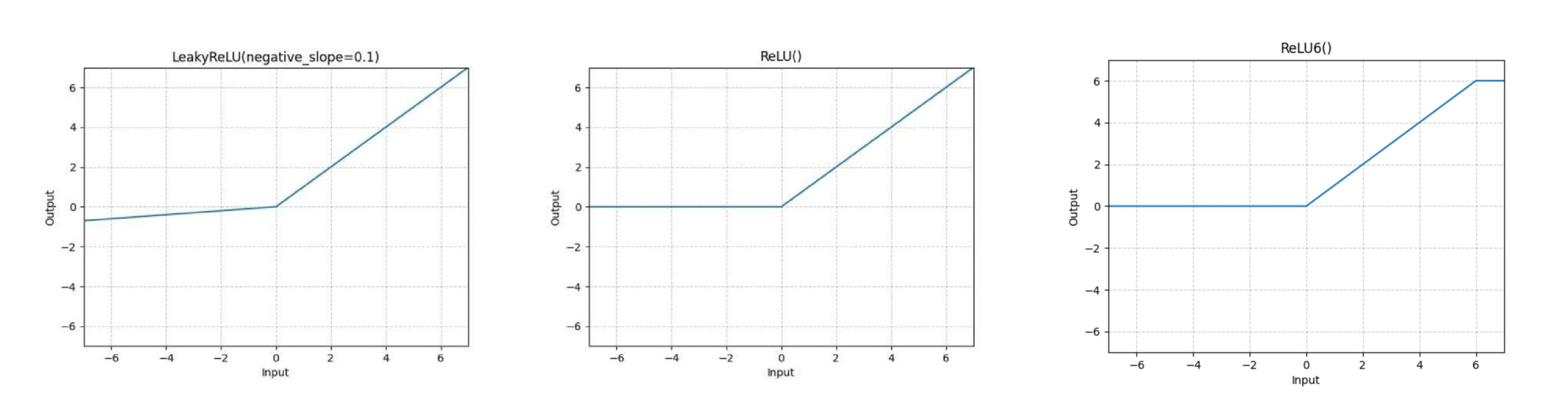
(Left) Leaky ReLU, (Middle) ReLU, (Right)ReLU6; taken from pytorch documentation
Other Linear Unit Variants
GELU
Gaussian Error Linear Unit
where is the cumulative distribution function of the standard normal distribution (mean = 0, standard deviation = 1)
There is an approximate version of GELU that is faster to compute but at the cost of exactness
or
Motivation for GELU 💡
The motivation mentioned in the paper is based on the following observations:
- ReLU determinstaically multiplies by 0 or 1
- Dropout ( A regularization Technique ) also multiplies by 0 or 1, but stochastically
- It is possible to multiple with the 0-1 mask stochastically while also depending on the input in the following way ( this is similar to Adaptive Dropout, zoneout ) the mask is given by
Since after the batch normaliztion anyway, this means that inputs have high probablity of getting dropped when decreases.
They say that we often want deterministic decision from the output, so they proposed GELU as the expected transformation of the stochastic regularizer.
I dont fully understand the motivation myself, but I guess having a partial idea is better than having no idea. They somehow want to take idea from dropout and activation functions and combine them to get a better activation function.
gelu = nn.GELU(approximate=False) # using the accurate version of GELUoutput = gelu(tensor)print(output)tensor([-0.1688, 0.8783, -0.1445, -0.1510, 0.4747, -0.0525, 1.3252, 1.4735, 0.5428, -0.1618])
SiLU / Swish
Sigmoid Linear Unit
where is the sigmoid function.
This is very similar to GELU but is used instead of
There is also a version of Swish with learneaable parameter.
where is a learnable parameter
silu = nn.SiLU()output = silu(tensor)print(output)tensor([-0.2518, 0.7628, -0.1713, -0.1825, 0.4206, -0.0544, 1.1579, 1.2948, 0.4780, -0.2051])
HardSwish
Introduced in Searching for MobileNetV3
It is actually implemented piecewise as follows:
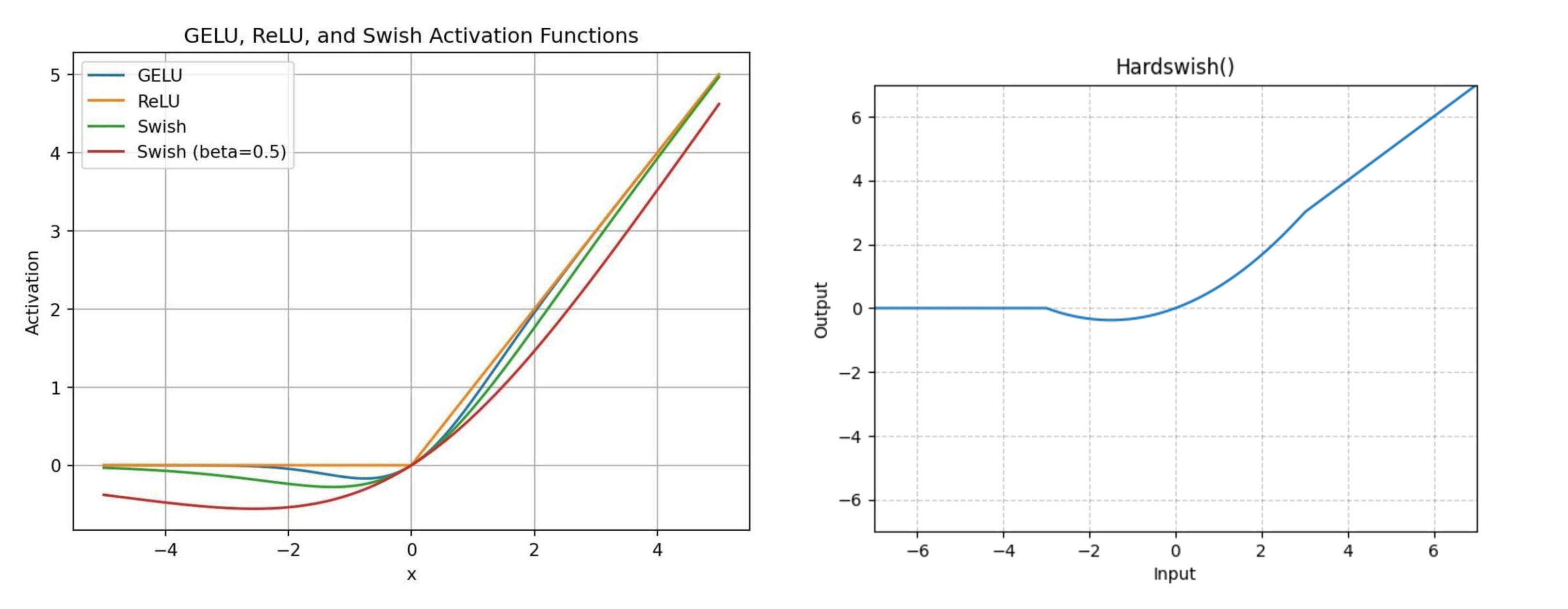
(Left)GELU, SiLU graphs from here ; (Right)Hard Swish from pytorch Documentation
GLU and variants
This section is heavily based on the paper GLU Variants improve Transfomers
GLU
Gated Linear Unit (GLU) : A neural network layer defined by component-wise product of two linear transformations of the input
They also suggest omitting the activation, whih they call a bilnear layer
Note: The bias term is often omitted
GLU Variants
Any activation function could be used in place of in the GLU equation, giving rise to a family of GLU variants.
\text{SiGLU}(x, W, V, b, c) = \text{SiLU(Wx + b)} \odot (Vx + c)\\\ \text{GeGLU}(x, W, V, b, c) = \text{GELU}(Wx + b) \odot (Vx + c)\\\Example Practical Implementation
# ReGLU could be implmeneted like this in pytorch
class ReGLU(nn.Module): def __init__(self): super(ReGLU, self).__init__() input_dim = 10 hidden_dim = 20 self.W = nn.Linear(input_dim, hidden_dim) self.V = nn.Linear(input_dim, hidden_dim) self.relu = nn.ReLU()
def forward(self, x): return self.W(x) * self.relu(self.V(x))
# Create a tensor with 10 random numberstensor = torch.randn(10)
# Create an instance of the ReGLU classreglu = ReGLU()
# Apply the ReGLU function to the tensoroutput = reglu(tensor)print(output)tensor([ 0.0000, 0.0074, 0.0000, -0.0000, -0.0753, -0.0598, -0.0000, -0.0000, -0.0000, 0.1110, -0.0109, 0.2933, -0.0185, 0.0000, -0.0016, 0.0250, 0.0000, 0.3512, 0.0000, 0.0000], grad_fn=<MulBackward0>)Implementations from Projects
Here are a few practical implementations from LLM models
GPT-2

GELU implementaiton from GPT-2 model definition.
GPT-2 uses an approximate version of GELU.
LLaMA

SwiGLU implementaiton from LLaMA model definition.
The python code
F.silu(self.w1(x)) * self.w3(x)is the SwiGLU implementation, the whole function is for the FFN ( MLP layer ) in the transformers.
Gemma
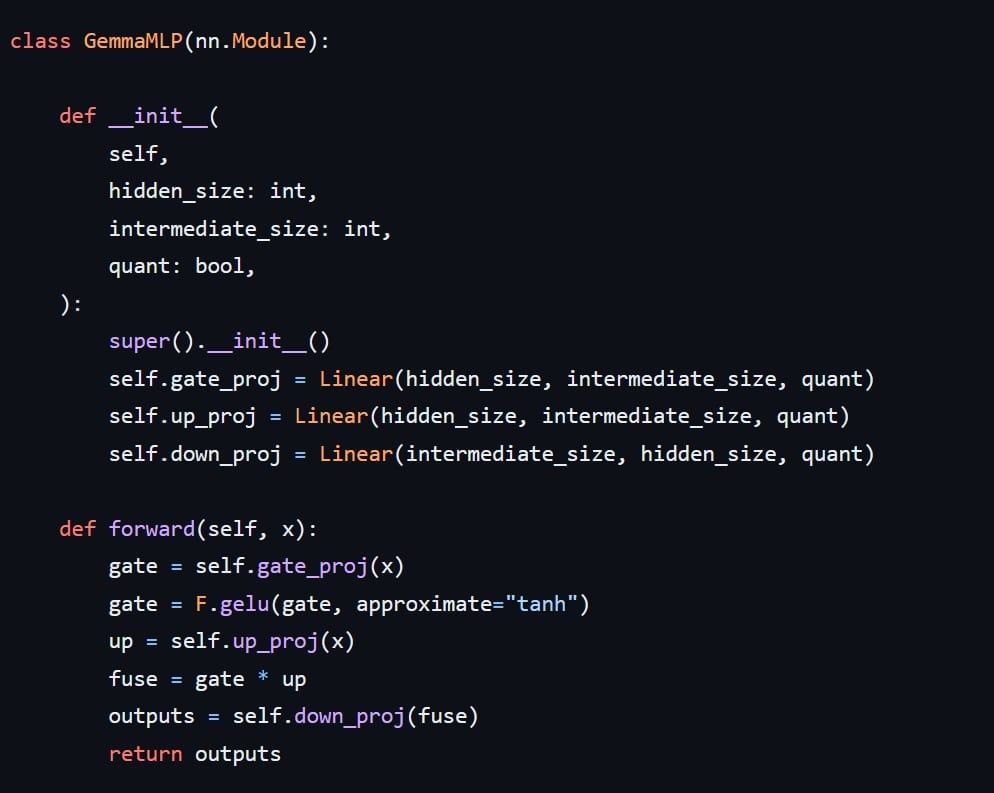
GeGLU implementaiton from Gemma model definition.
The GEGLU is a little more hidden in this function, the screenshot shows the whole FFN ( MLP layer ) function, but if you carefully observe you can make out the GEGLU implementation. (Hint look at the fuse variable)