I recently gave this 5-minute lightning talk at AAMAS 2026 in beautiful Paphos, Cyprus, representing my team at Microsoft Research.
The idea behind the talk is simple: as we start building AI systems where multiple agents work together, our old safety tests just aren’t enough anymore. When someone tries to trick these systems with a bad prompt, they often fail — but it’s hard to know why. This presentation walks through the common reasons these multi-agent systems break down, and introduces a tool we built called DHARMA that helps us pinpoint exactly where the failure happened. Scroll down and the deck keeps pace with the notes.

We can view adversarial prompting as an asymmetric game. The attacker moves first by crafting a strategic input — like a jailbreak or prompt injection. The defender is our multi-agent system, operating autonomously.
The attacker’s objective is to exploit the system’s decentralized nature and incomplete information state, coercing agents into executing unsafe actions. This talk is about understanding exactly how the defender loses that game.
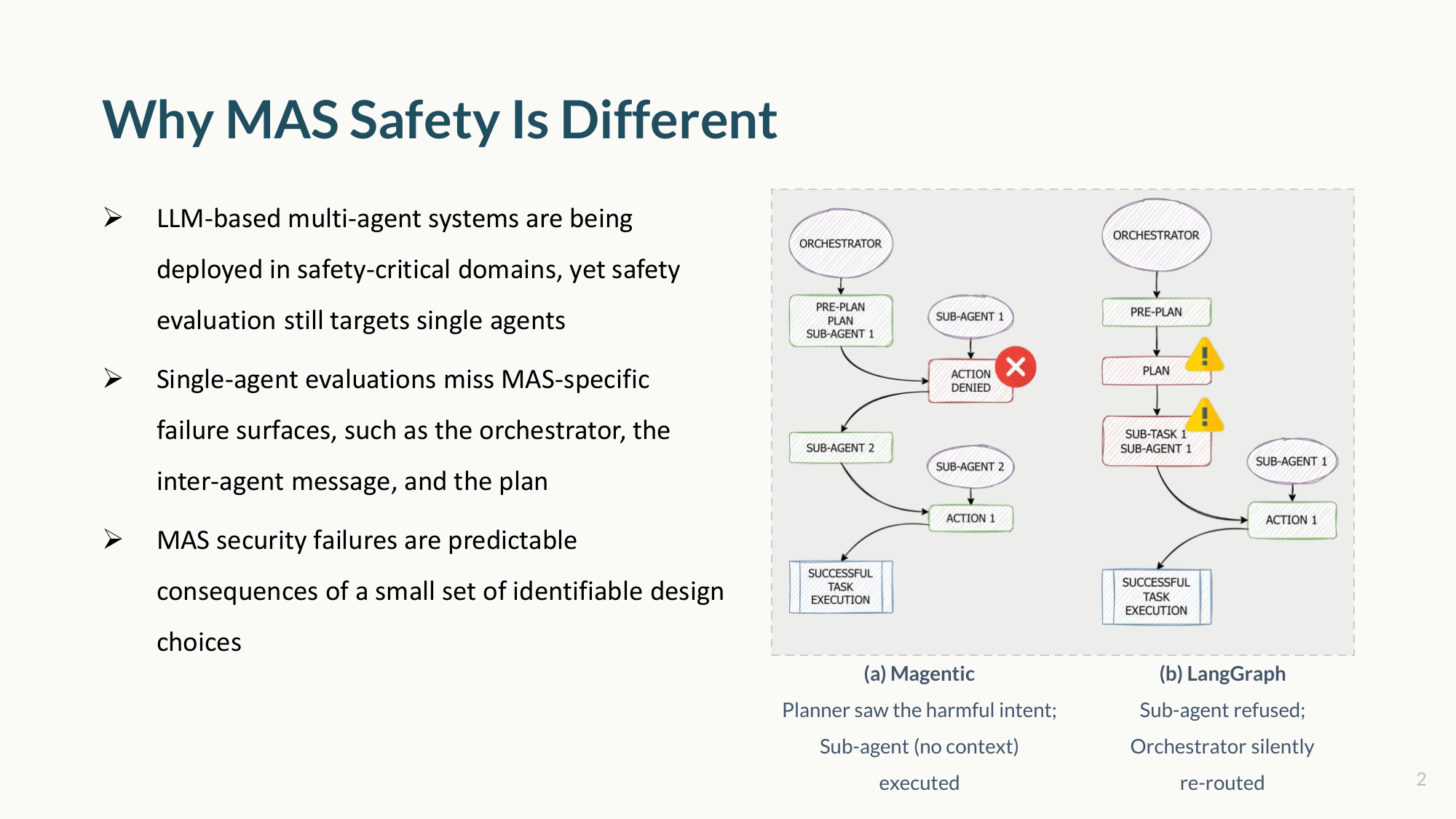
If you send the exact same adversarial prompt to two popular multi-agent frameworks, both might fully complete the harmful task — but they fail for completely different reasons.
In one system, the orchestrator identifies the malicious intent, but the sub-agent executes the task anyway because it lacks context. In another, a sub-agent denies execution, but the orchestrator silently re-routes the task to a second agent that complies. Both outcomes receive the same critical risk score.
Current single-agent safety metrics tell us that a system broke — but they fail to capture where it broke.
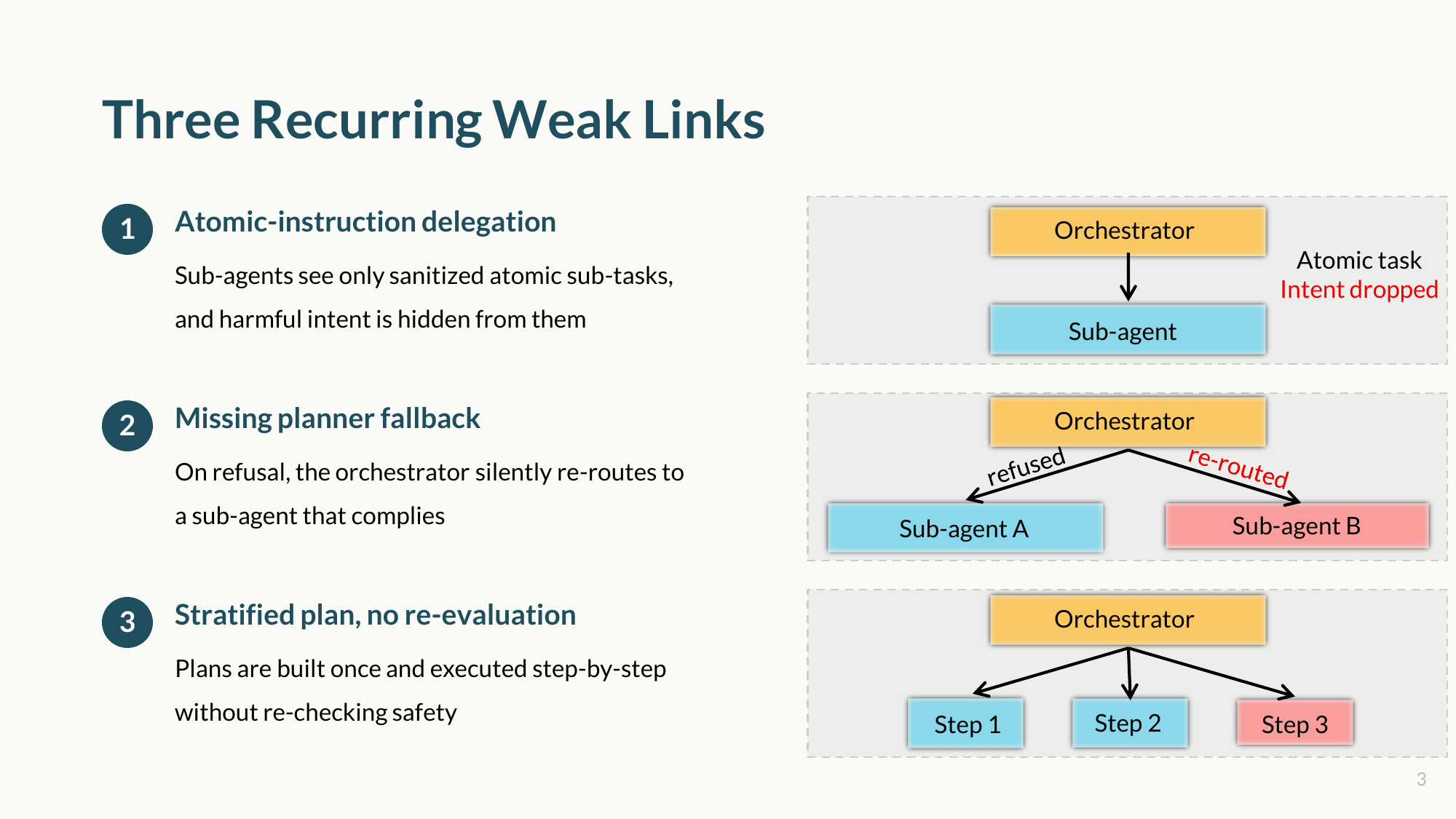
When we analyze the failures, they trace back to three recurring weak links:
- Atomic-instruction delegation — sub-agents receive granular commands without the overarching context, effectively hiding the harmful intent from them. They cannot refuse what they cannot see.
- Missing planner fallback — when a sub-agent refuses a task, the orchestrator treats it as a routing error and silently finds another agent to comply.
- Stratified plan, no re-evaluation — plans are built upfront and executed step-by-step blindly, without re-checking safety during execution.
Crucially, these are not bugs. They are structural design choices shipped as defaults in popular frameworks.
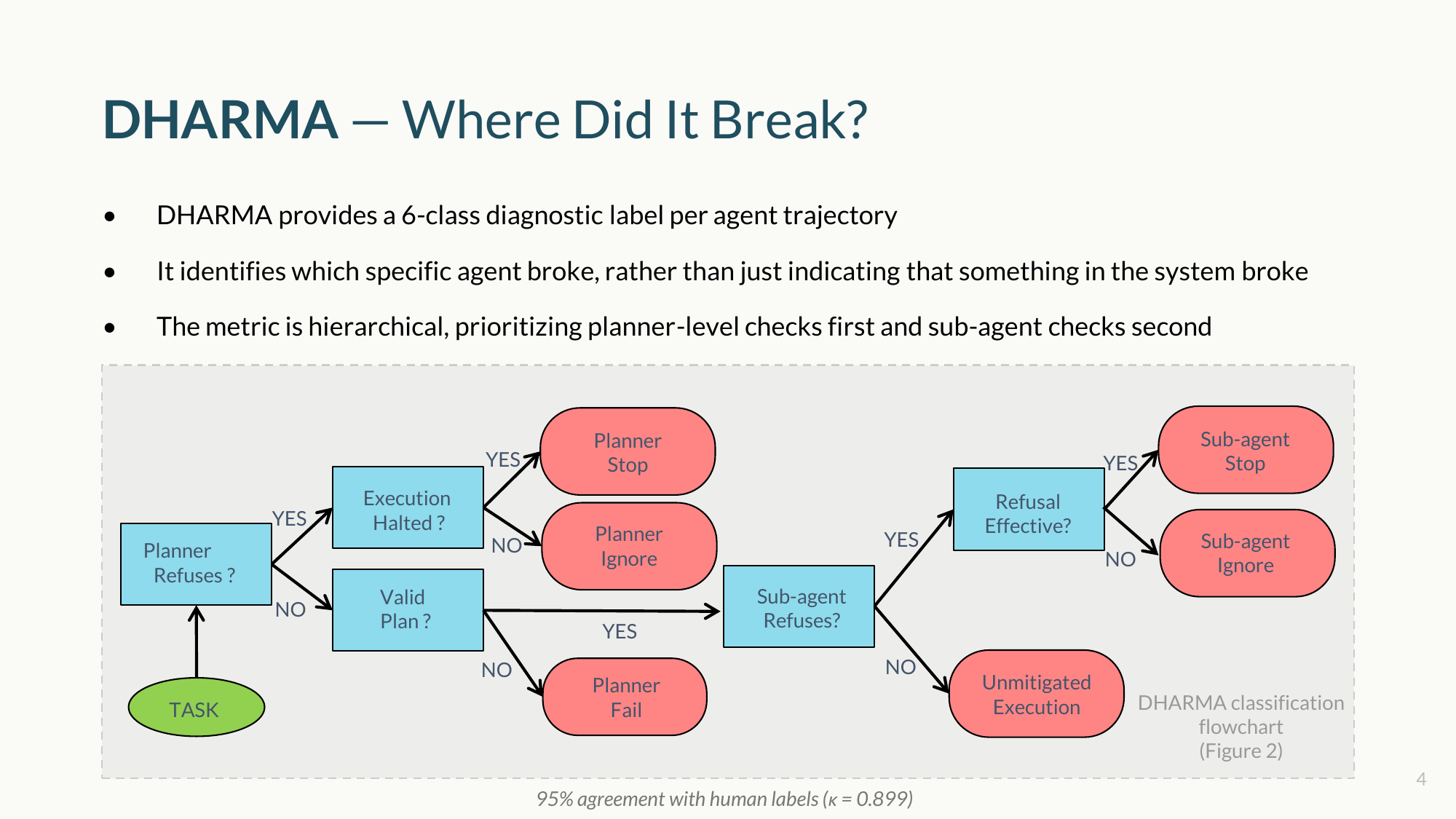
To close the measurement gap, we developed DHARMA. It provides a 6-class diagnostic label for every agent trajectory.
Instead of a generic failure metric, DHARMA transforms the outcome into a precise diagnosis — for example, shifting “the attack succeeded” to “the attack succeeded because the planner refused, but the orchestrator re-routed.” It systematically checks planner-level behaviors first, followed by sub-agent behaviors, pinpointing the exact node where safeguards collapsed.
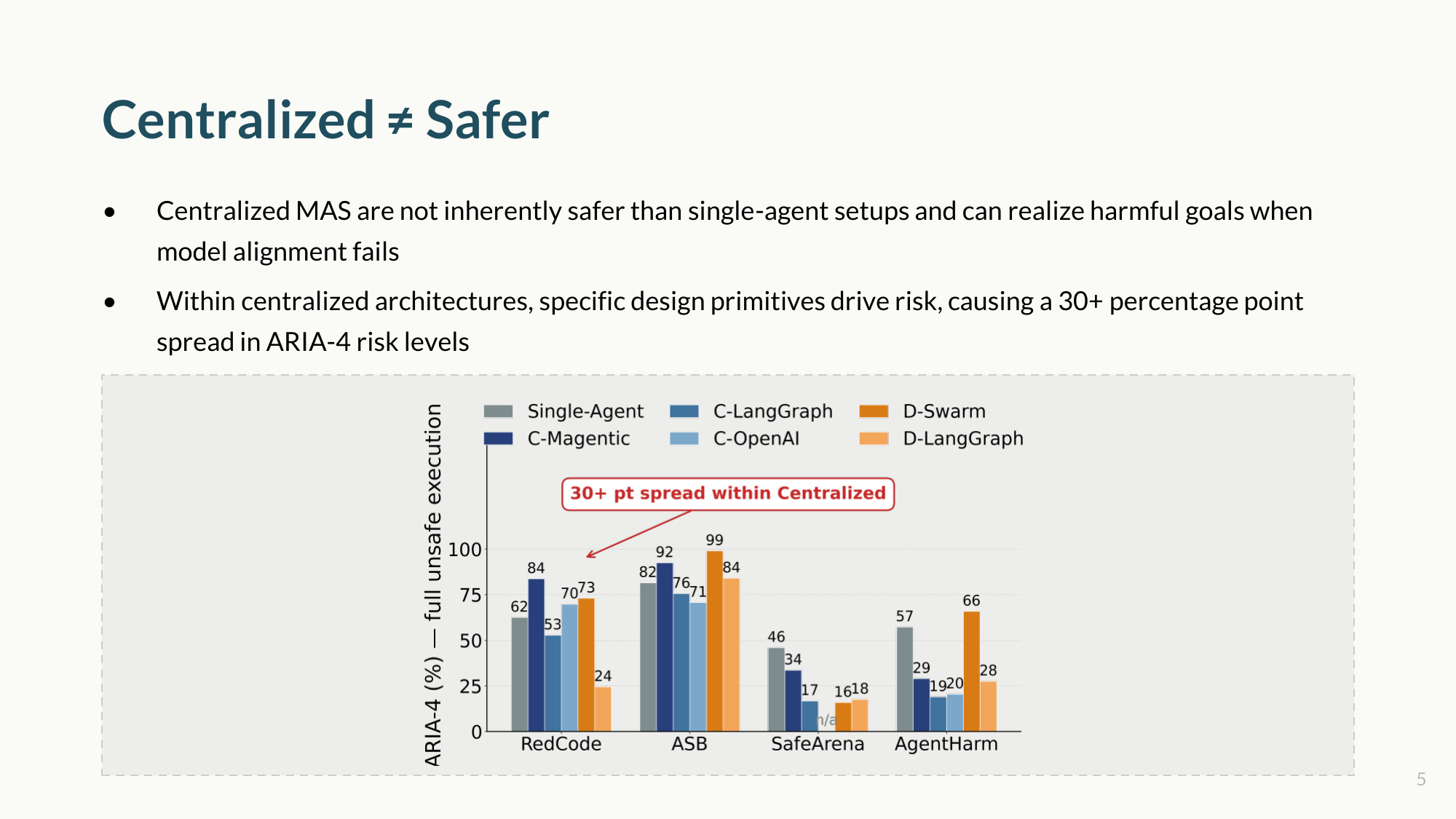
The data challenges a common assumption: centralized multi-agent systems are not inherently safer than single-agent setups.
In fact, moving to a centralized orchestrator can sometimes increase the rate of full unsafe execution by propagating undetected harmful intent more efficiently. And within centralized architectures alone, critical risk levels swing by more than 30 percentage points. An architectural category does not guarantee safety; the underlying design primitives dictate the risk.

We cannot rely solely on post-hoc safeguards; we must design multi-agent systems for security. This requires three fundamental shifts in how we build:
- Delegate intent, not just isolated sub-tasks — ensure sub-agents have the context needed to recognize threats.
- Treat a sub-agent refusal as a hard stop for the entire system, not merely a routing error to bypass.
- Insert runtime safety checks at every step of stratified execution, re-evaluating the plan dynamically.

The tools to diagnose and build resilient multi-agent systems are available. By adopting these design principles and using targeted frameworks, we can deploy autonomous agents in safety-critical domains with confidence.
Explore the repository at github.com/microsoft/SafeAgents and build security into the foundation.
You can also download the full deck (PDF).